Talking with U.T. Austin students about the Microformats, Drug Discovery, the Tabulator, and the Semantic Web
Working with the MIT tabulator students has been such a blast that while I was at U.T. Austin for the research library symposium, I thought I would try to recruit some undergrads there to get into it. Bob Boyer invited me to speak to his PHL313K class on why the heck they should learn logic, and Alan Cline invited me to the Dean's Scholars lunch, which I used to attend when I was at U.T.
To motivate logic in the PHL313K class, I started with their experience with HTML and blogging and explained how the Semantic Web extends the web by looking at links as logical propositions.  I used my XML 2005 slides to talk a little bit about web history and web architecture, and then I moved into using hCalendar (and GRDDL, though I left that largely implicit) to address the personal information disaster. This was the first week or so of class and they had just started learning propositional logic, and hadn't even gotten as far as predicate calculus where atomic formulas like those in RDF show up. And none of them had heard of microformats. I promised not to talk for the full hour but then lost track of time and didn't get to the punch line, "so the computer tells you that no, you can't go to both the conference and Mom's birthday party because you can't be in two places at once" until it was time for them to head off to their next class.
I used my XML 2005 slides to talk a little bit about web history and web architecture, and then I moved into using hCalendar (and GRDDL, though I left that largely implicit) to address the personal information disaster. This was the first week or so of class and they had just started learning propositional logic, and hadn't even gotten as far as predicate calculus where atomic formulas like those in RDF show up. And none of them had heard of microformats. I promised not to talk for the full hour but then lost track of time and didn't get to the punch line, "so the computer tells you that no, you can't go to both the conference and Mom's birthday party because you can't be in two places at once" until it was time for them to head off to their next class.
One student did stay after to pose a question that is very interesting and important, if only tangentially related to the Semantic Web: with technology advancing so fast, how do you maintain balance in life?
While Boyer said that talk went well, I think I didn't do a very good job of connecting with them; or maybe they just weren't really awake; it was an 8am class after all. At the Dean's Scholars lunch, on the other hand, the students were talking to each other so loudly as they grabbed their sandwiches that Cline had to really work to get the floor to introduce me as a "local boy done good." They responded with a rousing ovation.
Elaine Rich had provided the vital clue for connecting with this audience earlier in the week. She does AI research and had seen TimBL's AAAI talk. While she didn't exactly give the talk four stars overall, she did get enough out of it to realize it would make an interesting application to add to a book that she's writing, where she's trying to give practical examples that motivate automata theory. So after I took a look at what she had written about URIs and RDF and OWL and such, she reminded me that not all the Deans Scholars are studying computer science; but many of them do biology, and I might do well to present the Semantic Web more from the perspective of that user community.
So I used TimBL's Bio-IT slides. They weren't shy when I went too fast with terms like hypertext, and there were a lot of furrowed brows for a while. But when I got to the 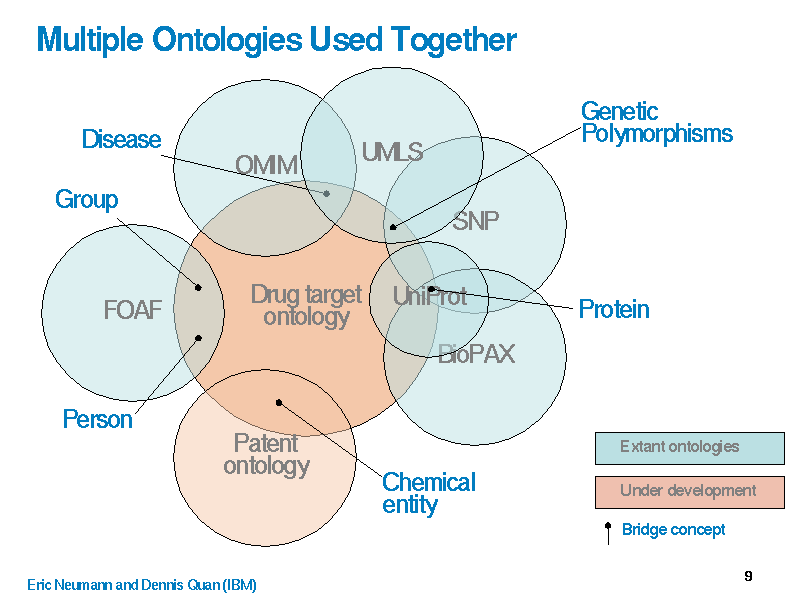 drug discovery diagram, I said I didn't even know some of these words and asked them which ones they knew. After a chuckle about "drug", one of them explained about SNP, i.e. single nucleotide polymorphism and another told me about OMM and the discussion really got going. I didn't make much more use of Tim's slides. One great question about integrating data about one place from lots of sources prompted me to tempt the demo gods and try the tabulator. The demo gods were not entirely kind; perhaps I should have used the released version rather than the development version. But I think I did give them a feel for it. In answer to "so what is it you're trying to do, exactly?" I gave a two part answer:
drug discovery diagram, I said I didn't even know some of these words and asked them which ones they knew. After a chuckle about "drug", one of them explained about SNP, i.e. single nucleotide polymorphism and another told me about OMM and the discussion really got going. I didn't make much more use of Tim's slides. One great question about integrating data about one place from lots of sources prompted me to tempt the demo gods and try the tabulator. The demo gods were not entirely kind; perhaps I should have used the released version rather than the development version. But I think I did give them a feel for it. In answer to "so what is it you're trying to do, exactly?" I gave a two part answer:
- Recruit some of them to work on the tabulator so that their name might be on the next paper like the SWUI06 paper, Tabulator: Exploring and Analyzing linked data on the Semantic Web.
- Integrate data accross applications and accross administrative boundaries all over the world, like the Web has done for documents.
We touched on the question of local and global consistency, and someone asked if you can reason about disagreement. I said that yes, I had presented a paper in Edinburgh just this May that demonstrated formally a disagreement between several parties
One of the last questions was "So what is computer science research anway?" which I answered by appeal to the DIG mission statement:
The Decentralized Information Group explores technical, institutional and public policy questions necessary to advance the development of global, decentralized information environments.
And I said how cool it is to have somebody in the TAMI project with real-world experience with the privacy act. One student followed up and asked if we have anybody with real legal background in the group, and I pointed him to Danny. He asked me afterward how to get involved, and it turned out that IRC and freenode are known to him, so the #swig channel was in our common neighborhood in cyberspace, even geography would separate us as I headed to the airport to fly home.
technorati tags:Austin, semantic, web
Blogged with Flock